Alaaeldin El-NoubyI am an AI Research PhD student at Meta AI (FAIR) and DI ENS/INRIA Paris, advised by Ivan Laptev, Natalia Neverova and Hervé Jégou. I have previously interned at Apple Inc. under the supervision of Joshua M Susskind and Shuangfei Zhai. I have also interned at Microsoft Research Montreal with Shikhar Sharma. I have worked as a Research Engineer at Microsoft ATLC I have a MSc in Computer Engineering from University of Guelph, where I was advised by Dr. Graham Taylor. During that time, I was a student researcher at the Vector Institute. Email: alaaelnouby-at-gmail.com / Google Scholar / Resume |

|
News
|
ResearchI'm interested in vision transformers, self-supervised learning, language-vision pre-training, multi-modal learning, image retrieval, and image compression. |
|
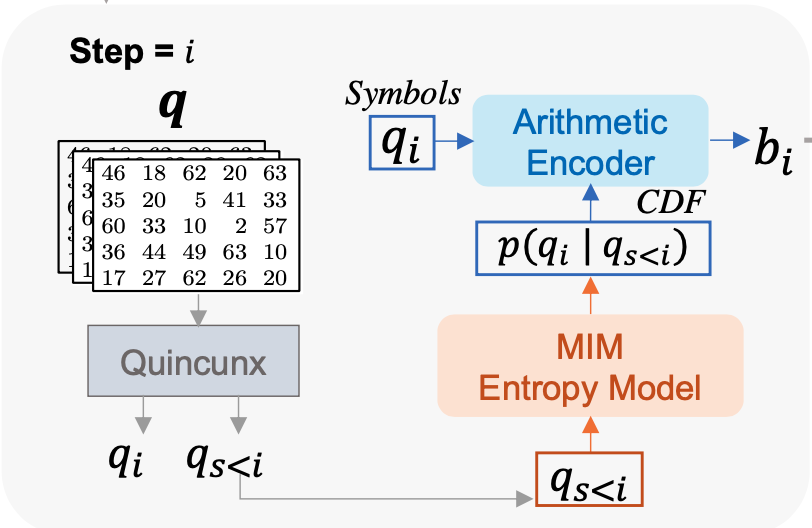
Image Compression with Product Quantized Masked Image ModelingAlaaeldin El-Nouby, Matthew J. Muckley, Karen Ullrich, Ivan Laptev, Jakob Verbeek, Hervé Jégou Transactions of Machine Learning Research (TMLR) arxiv / In this work, we attempt to bring image generation and neural compression lines of research closer by revisiting vector quantization for image compression. First, we replace the vanilla vector quantizer by a product quantizer. Second, inspired by the success of Masked Image Modeling (MIM) in the context of self-supervised learning and generative image models, we propose a novel conditional entropy model which improves entropy coding by modelling the co-dependencies of the quantized latent codes. The resulting PQ-MIM model is surprisingly effectiv, we explore the extreme compression regime where an image is compressed into 200 bytes, i.e., less than a tweet. |
|
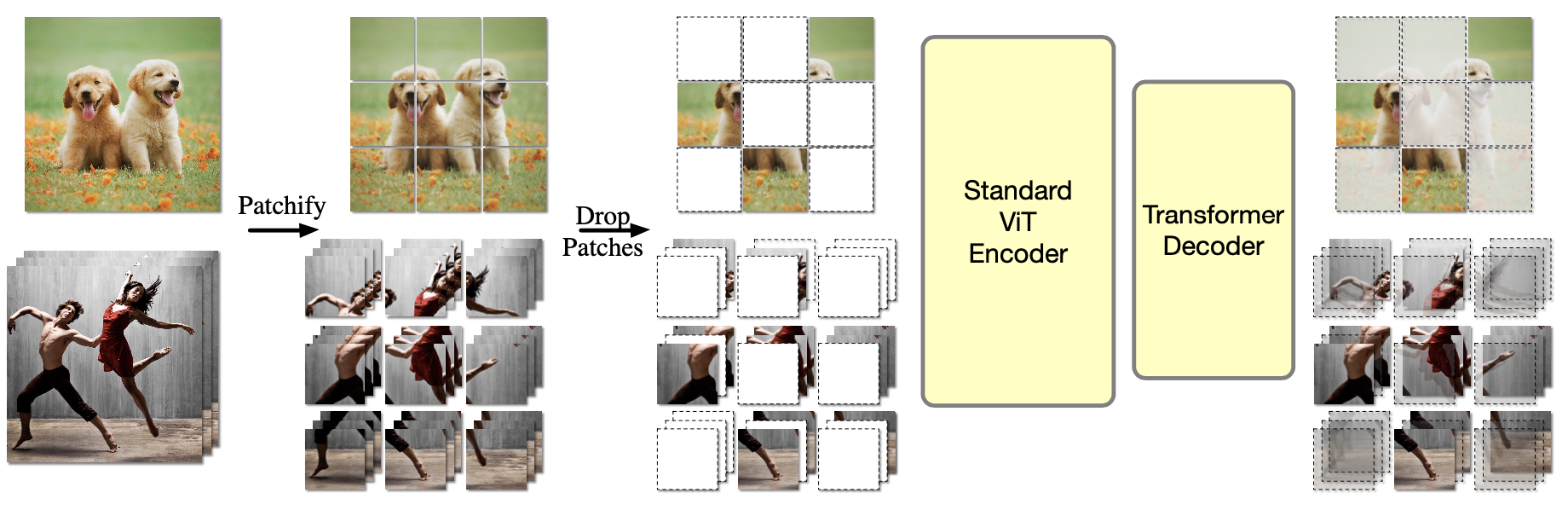
OmniMAE: Single Model Masked Pretraining on Images and VideosRohit Girdhar*, Alaaeldin El-Nouby*, Mannat Singh*, Kalyan Vasudev Alwala*, Armand Joulin, Ishan Misra* CVPR 2023 arxiv / code / In this work, we show that masked autoencoding can be used to train a simple Vision Transformer on images and videos, without requiring any labeled data. This single model learns visual representations that are comparable to or better than single-modality representations on both image and video benchmarks, while using a much simpler architecture. In particular, our single pretrained model can be finetuned to achieve 86.5% on ImageNet and 75.3% on the challenging Something Something-v2 video benchmark. Furthermore, this model can be learned by dropping 90% of the image and 95% of the video patches, enabling extremely fast training. |
|
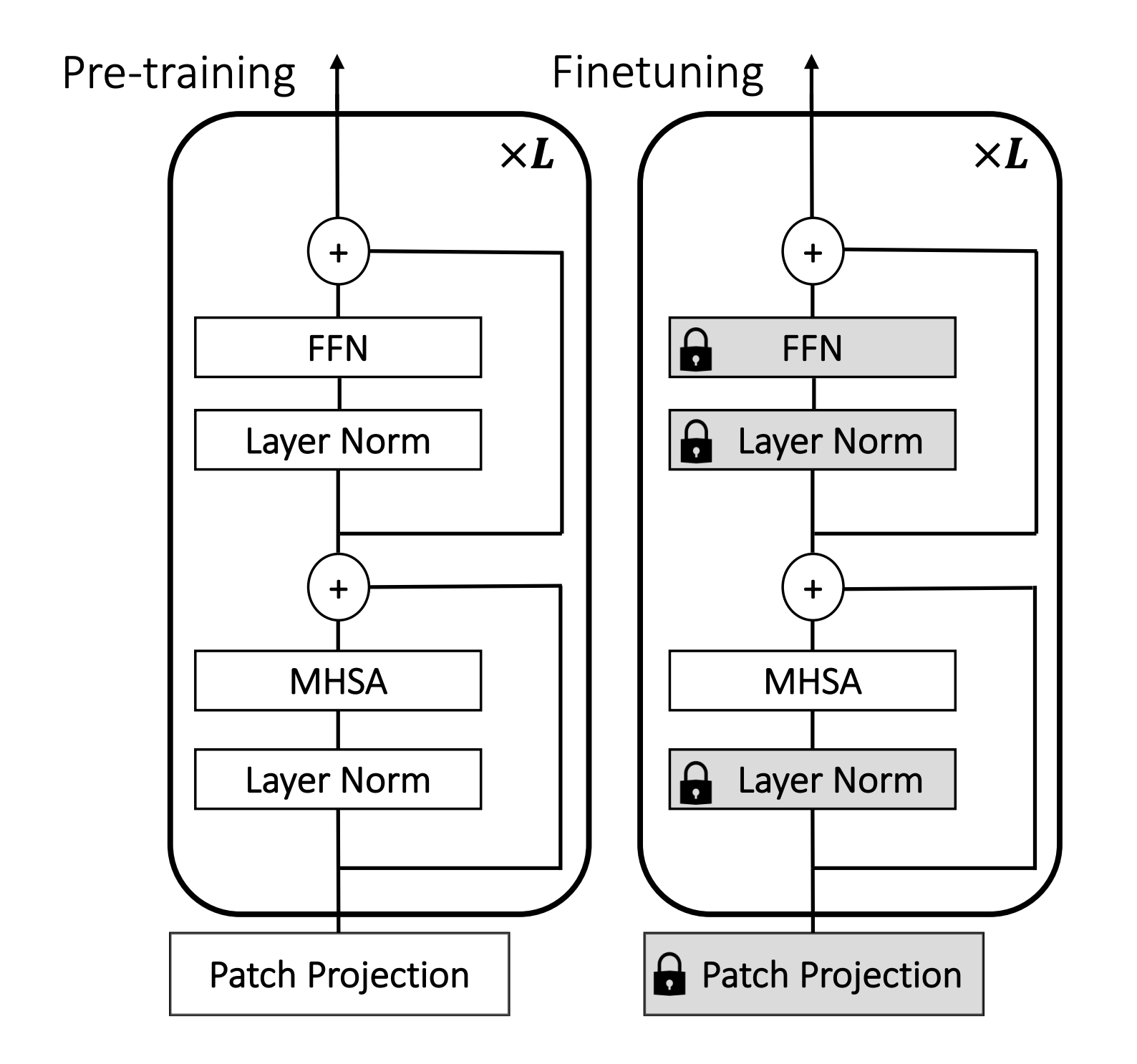
Three things everyone should know about Vision TransformersHugo Touvron, Matthieu Cord, Alaaeldin El-Nouby, Jakob Verbeek, Hervé Jégou ECCV 2022 arxiv / code / We offer three insights based on simple and easy to implement variants of vision transformers. (1) The residual layers of vision transformers, which are usually processed sequentially, can to some extent be processed efficiently in parallel without noticeably affecting the accuracy. (2) Fine-tuning the weights of the attention layers is sufficient to adapt vision transformers to a higher resolution and to other classification tasks. This saves compute, reduces the peak memory consumption at fine-tuning time, and allows sharing the majority of weights across tasks. (3) Adding MLP-based patch pre-processing layers improves Bert-like self-supervised training based on patch masking. We evaluate the impact of these design choices using the ImageNet-1k dataset, and confirm our findings on the ImageNet-v2 test set. Transfer performance is measured across six smaller datasets. |
|
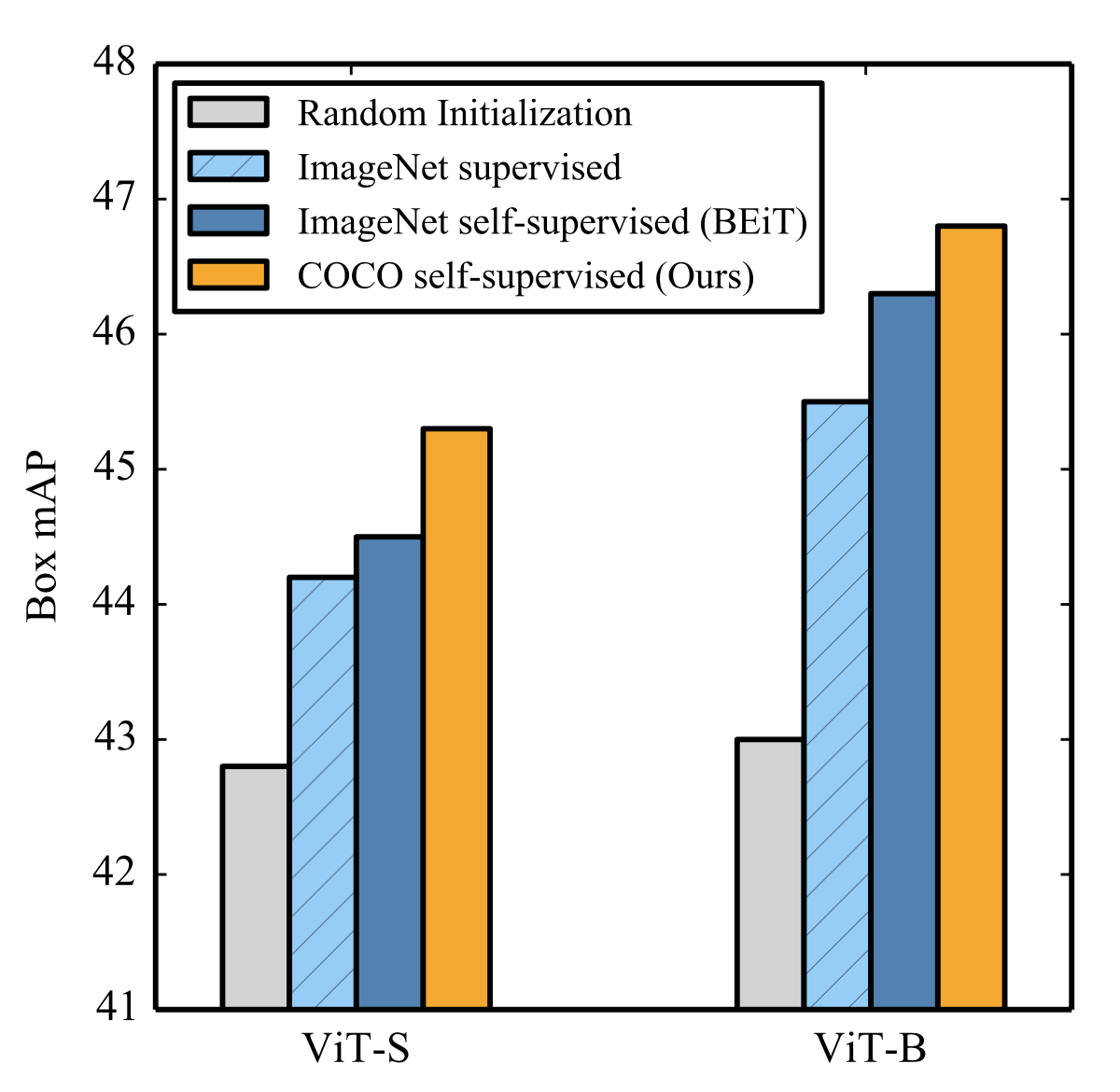
Are Large-scale Datasets Necessary for Self-Supervised Pre-training?Alaaeldin El-Nouby*, Gautier Izacard*, Hugo Touvron, Ivan Laptev, Hervé Jegou, Edouard Grave Under Review arxiv / Pre-training models on large scale datasets, like ImageNet, is a standard practice in computer vision. We consider a self-supervised pre-training scenario that only leverages the target task data. We consider datasets, like Stanford Cars, Sketch or COCO, which are order(s) of magnitude smaller than Imagenet. Our study shows that denoising autoencoders, such as BEiT or a variant that we introduce in this paper, are more robust to the type and size of the pre-training data than popular self-supervised methods trained by comparing image embeddings. |
|
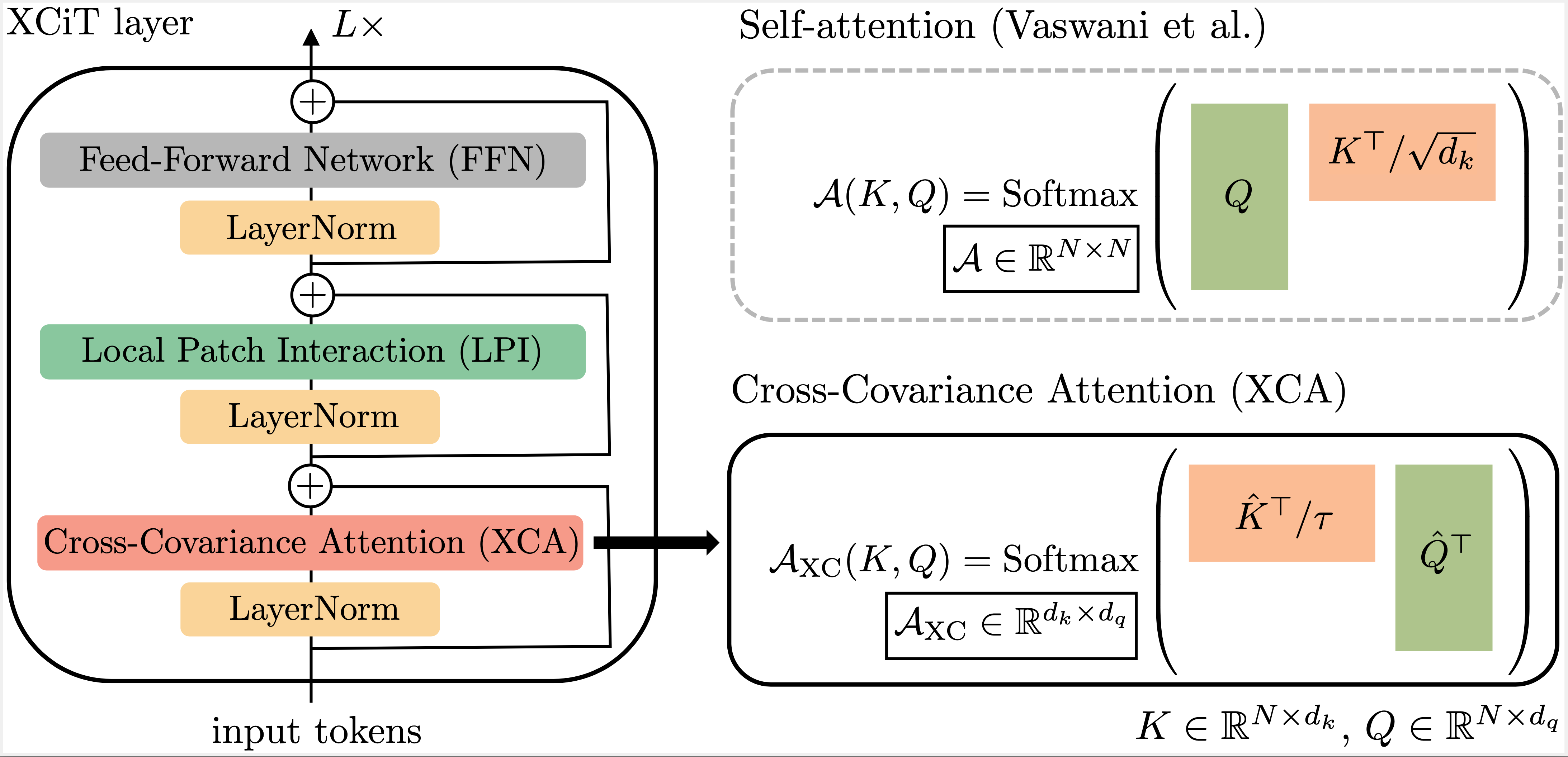
XCiT: Cross-Covariance Image TransformerAlaaeldin El-Nouby, Hugo Touvron, Mathilde Caron, Piotr Bojanowski, Matthijs Douze, Armand Joulin, Ivan Laptev, Natalia Neverova, Gabriel Synnaeve, Jakob Verbeek, Hervé Jegou NeurIPS 2021 arxiv / video / code / We propose a “transposed” version of self-attention that operates across feature channels rather than tokens. The resulting cross-covariance attention (XCA) has linear complexity in the number of tokens. Our cross-covariance image transformer (XCiT) is built upon XCA. It combines the accuracy of conventional transformers with the scalability of convnets. XCiT povides excellent results on multiple vision benchmarks, including image classification and self-supervised feature learning on ImageNet-1k, object detection and instance segmentation on COCO, and semantic segmentation on ADE20k. |
|
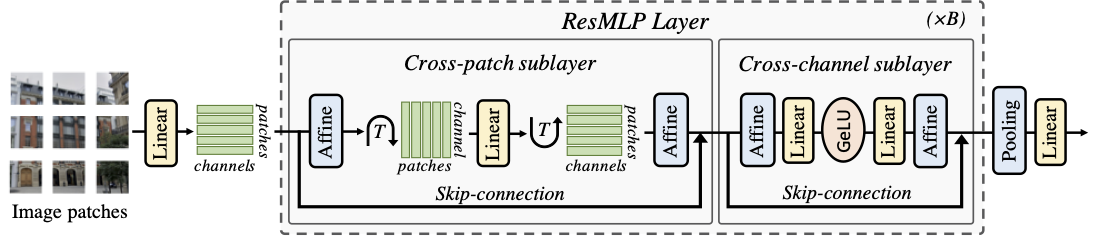
ResMLP: Feedforward networks for image classification with data-efficient trainingHugo Touvron, Piotr Bojanowski, Mathilde Caron, Matthieu Cord, Alaaeldin El-Nouby, Edouard Grave, Gautier Izacard, Armand Joulin, Gabriel Synnaeve, Jakob Verbeek, Hervé Jégou TPAMI arxiv / code / We present ResMLP, an architecture built entirely upon multi-layer perceptrons for image classification. It is a simple residual network that alternates (i) a linear layer in which image patches interact, independently and identically across channels, and (ii) a two-layer feed-forward network in which channels interact independently per patch. |
|
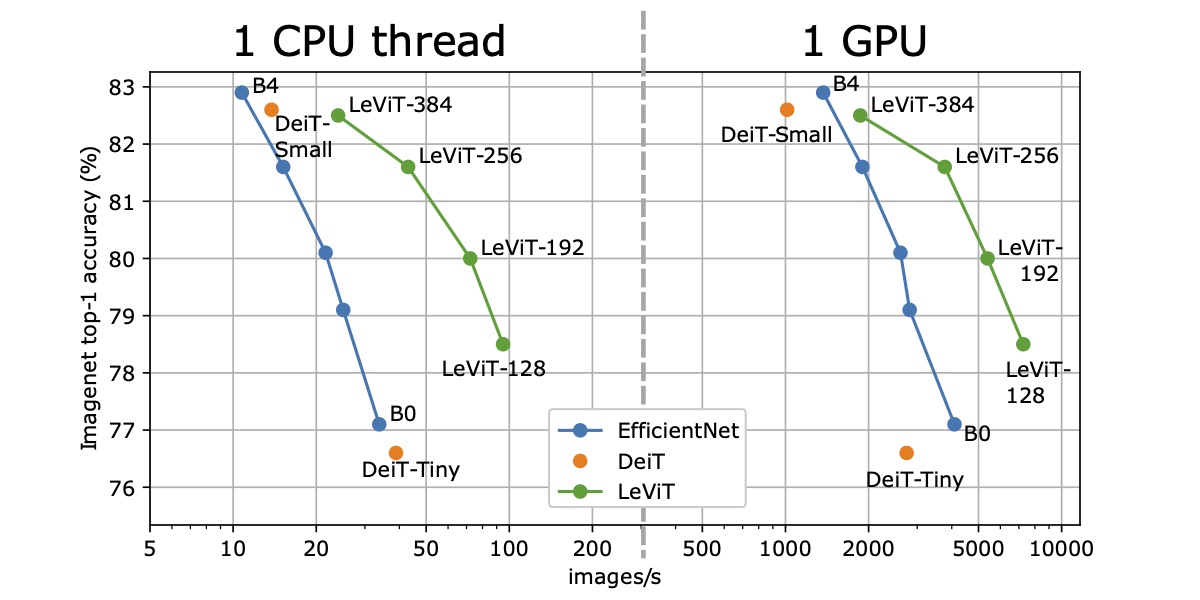
LeViT: a Vision Transformer in ConvNet's Clothing for Faster InferenceBen Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze ICCV 2021 arxiv / code / We propose LeVIT: a hybrid neural network for fast inference image classification. We consider different measures of efficiency on different hardware platforms, so as to best reflect a wide range of application scenarios. Our extensive experiments empirically validate our technical choices and show they are suitable to most architectures. Overall, LeViT significantly outperforms existing convnets and vision transformers with respect to the speed/accuracy tradeoff. For example, at 80\% ImageNet top-1 accuracy, LeViT is 3.3 times faster than EfficientNet on the CPU. |
|
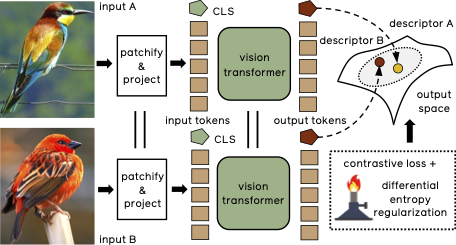
Training Vision Transformers for Image RetrievalAlaaeldin El-Nouby, Natalia Neverova, Ivan Laptev, Hervé Jégou Preprint arxiv / We adopt vision transformers for generating image descriptors and train the resulting model with a metric learning objective, which combines a contrastive loss with a differential entropy regularizer. Our results show consistent and significant improvements of transformers over convolution-based approaches. In particular, our method outperforms the state of the art on several public benchmarks for category-level retrieval, namely Stanford Online Product, In-Shop and CUB-200. |
|
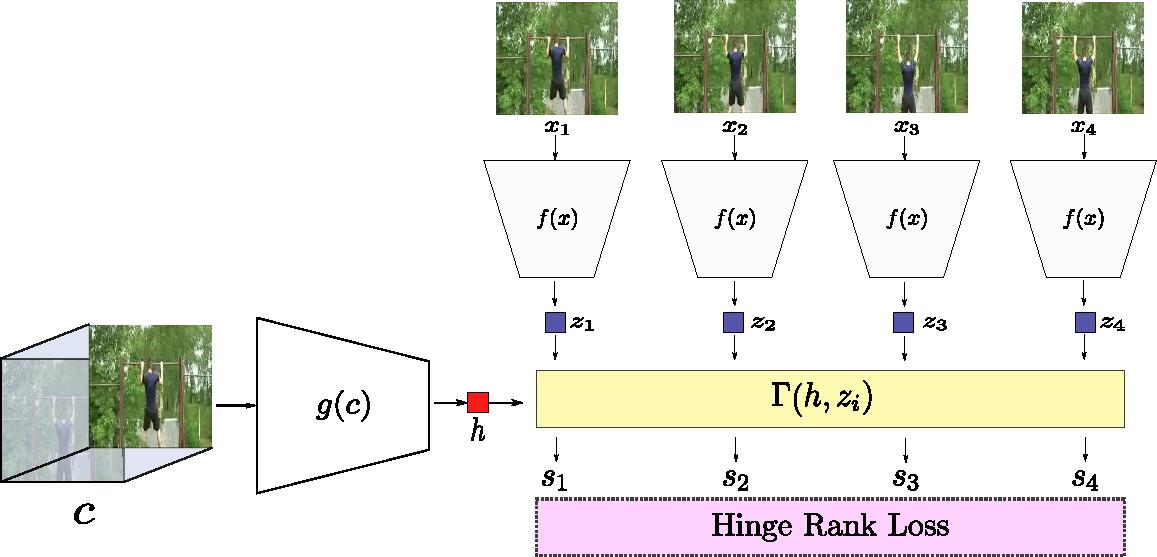
Skip-Clip: Self-Supervised Spatiotemporal Representation Learning by Future Clip Order RankingAlaaeldin El-Nouby, Shuangfei Zhai, Graham W. Taylor, Joshua M. Susskind Holistic Video Understanding Workshop ICCV2019 (Best poster Award) arxiv / poster / bibtex / We introduce Skip-Clip, a method that utilizes temporal coherence in videos, by training a deep model for future clip order ranking conditioned on a context clip as a surrogate objective for video future prediction. We show that features learned using our method are generalizable and transfer strongly to downstream tasks. |
|
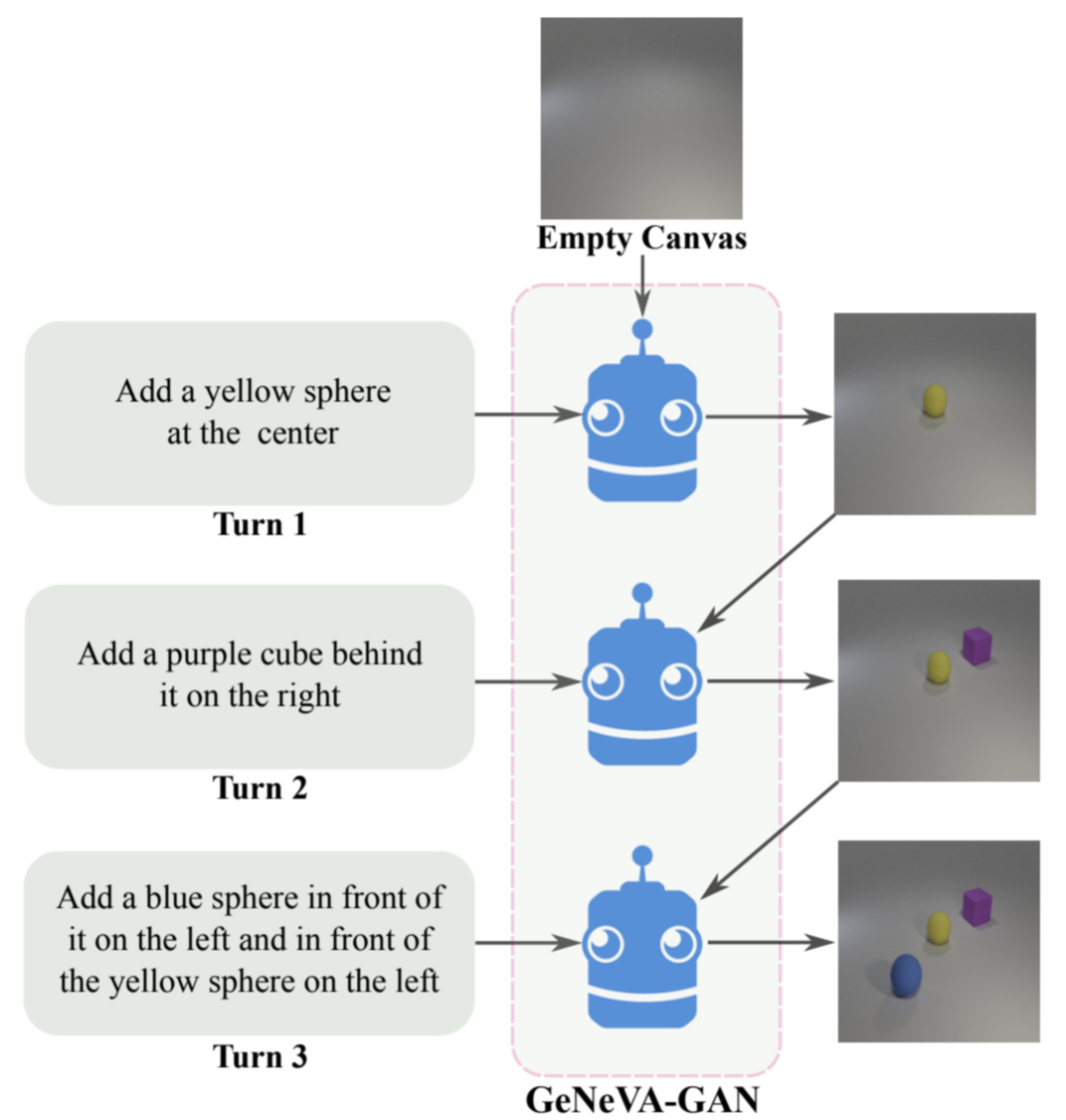
Tell, Draw, and Repeat: Generating and Modifying Images Based on Continual Linguistic InstructionAlaaeldin El-Nouby, Shikhar Sharma, Hannes Schulz, Devon Hjelm, Layla El Asri, Samira Ebrahimi Kahou, Yoshua Bengio, Graham W.Taylor Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV) arxiv / code / poster / blog / bibtex / In this work, we present a recurrent image generation model which takes into account both the generated output up to the current step as well as all past instructions for generation. We show that our model is able to generate the background, add new objects, and apply simple transformations to existing objects. |
|
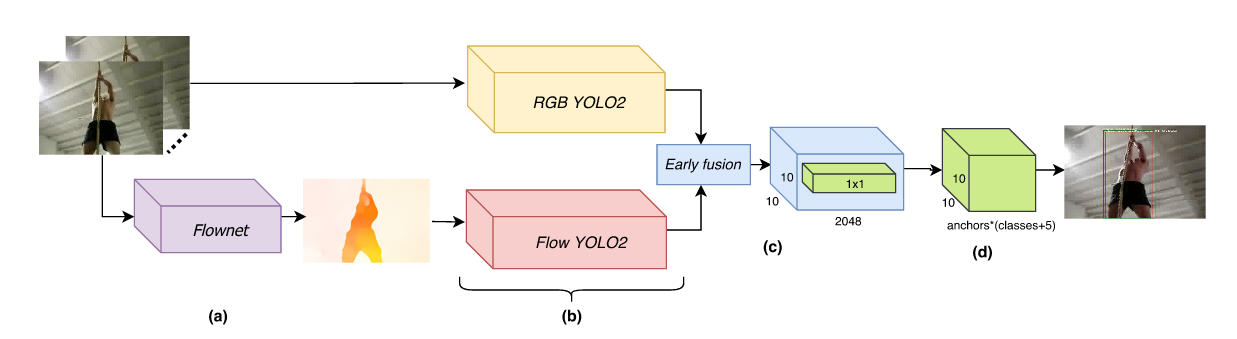
Real-Time End-to-End Action Detection with Two-Stream NetworksAlaaeldin El-Nouby, Graham W. Taylor 15th Conference on Computer and Robot Vision, CRV 2018 (Oral) arxiv / bibtex / We present a real-time end-to-end trainable two-stream network for action detection. First, we integrate the optical flow computation in our framework by using Flownet2. Second, we apply early fusion for the two streams and train the whole pipeline jointly end-to-end. Finally, for better network initialization, we transfer from the task of action recognition to action detection by pre-training our framework using the recently released large-scale Kinetics dataset. |

|
Spatiotemporal Representation Learning For Human Action Recognition And LocalizationAlaaeldin El-Nouby arxiv / bibtex / A Thesis presented toThe University of Guelph In partial fulfilment of requirements for the degree of Master of Applied Science in Engineering |
Invited Talks
|
Reviewing
|
|
Design and source code from Jon Barron's website |