Alaaeldin El-NoubyI am a Staff Research Scientist at Meta Superintelligence Labs (FAIR) working on agentic coding post-training and previously LLM pre-training. Before that, I was part of the MLR team at Apple where I led research in scaling vision and multimodal pre-training. I completed my PhD in Computer Science at Meta AI (FAIR) and École Normale Supérieure, advised by Ivan Laptev, Natalia Neverova, and Hervé Jégou. I have a MSc in Computer Engineering from University of Guelph, where I was advised by Dr. Graham Taylor. During that time, I was a student researcher at the Vector Institute. Email: alaaelnouby-at-gmail.com / Google Scholar / Resume |

|
News
|
ResearchI'm interested in agentic coding post-training, LLM pre-training, multimodal vision language models, large-scale visual representation learning. |
|
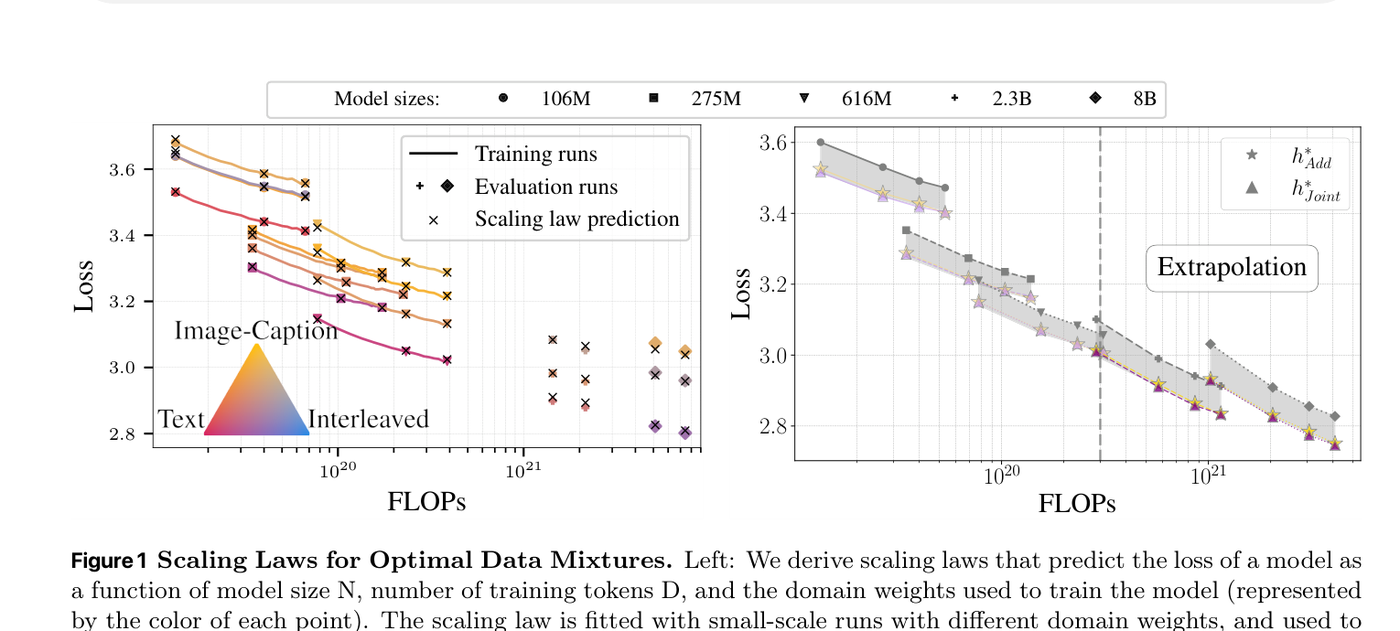
Scaling Laws for Optimal Data Mixtures
NeurIPS 2025
paper
|
|
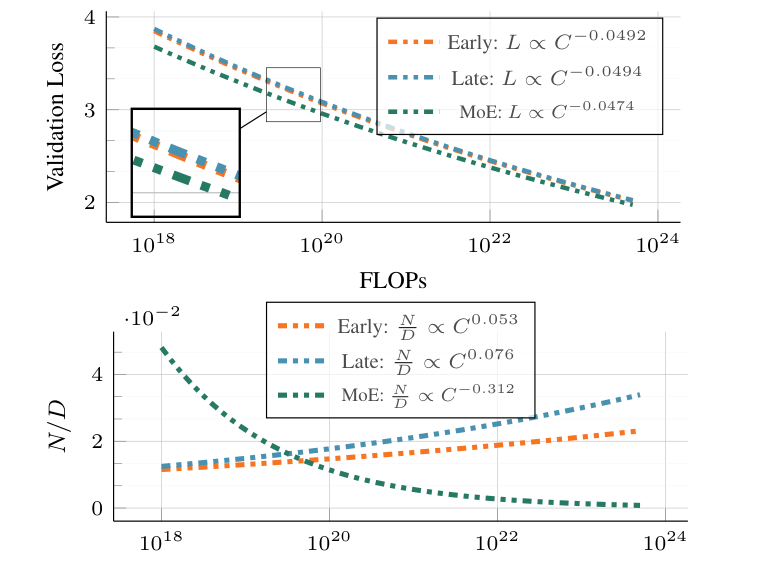
Scaling Laws for Native Multimodal Models
ICCV 2025
Oral
paper
|

|
FlexTok: Resampling Images into 1D Token Sequences of Flexible Length
ICML 2025
paper
code
|
|
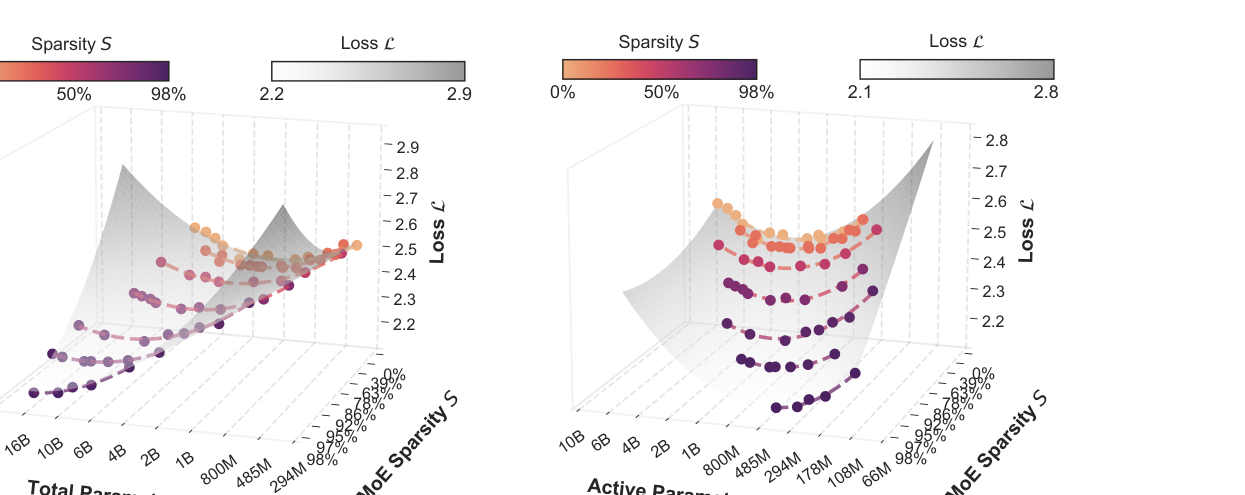
Parameters vs FLOPs: Scaling Laws for Optimal Sparsity for Mixture-of-Experts Language Models
ICML 2025
paper
|
|
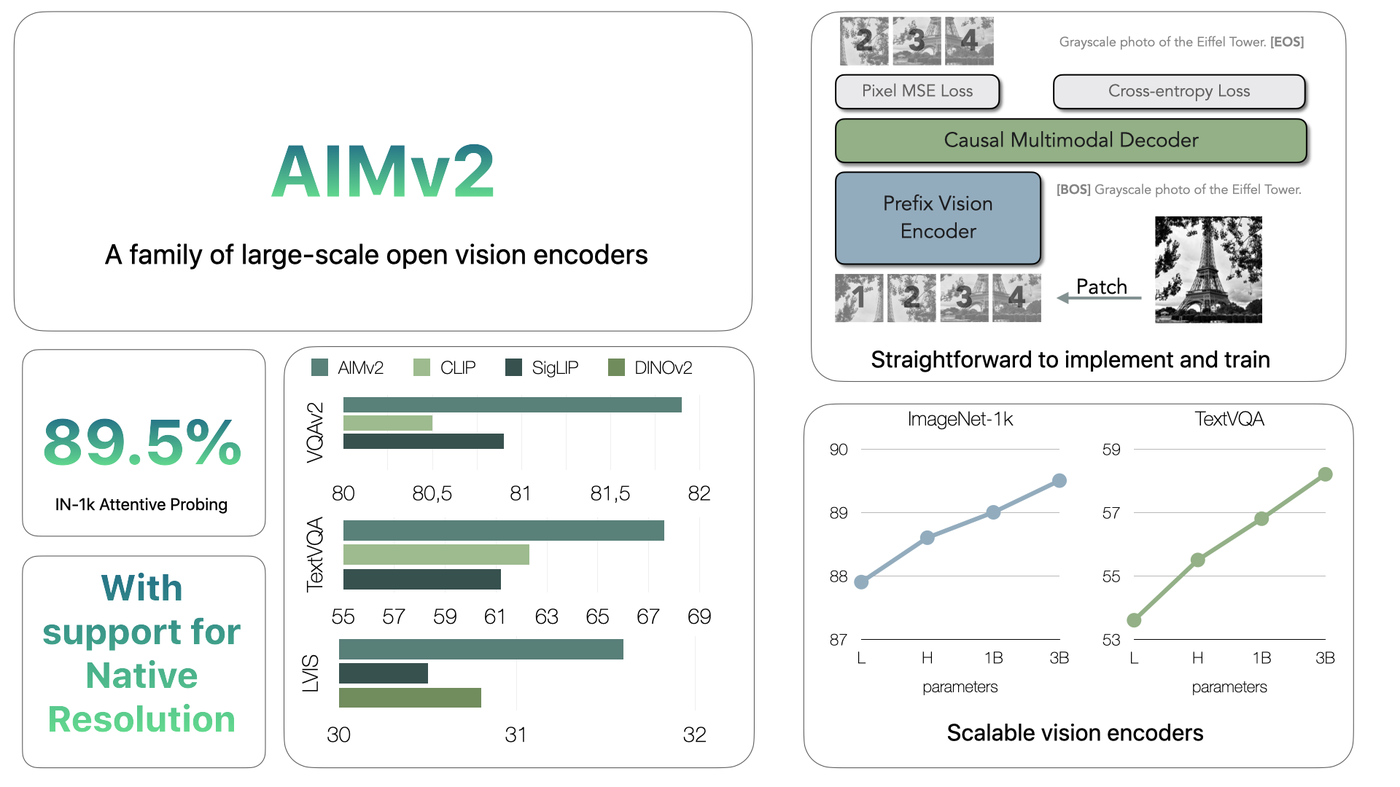
Multimodal Autoregressive Pre-training of Large Vision Encoders
CVPR 2025
Highlight
paper
code
|
|
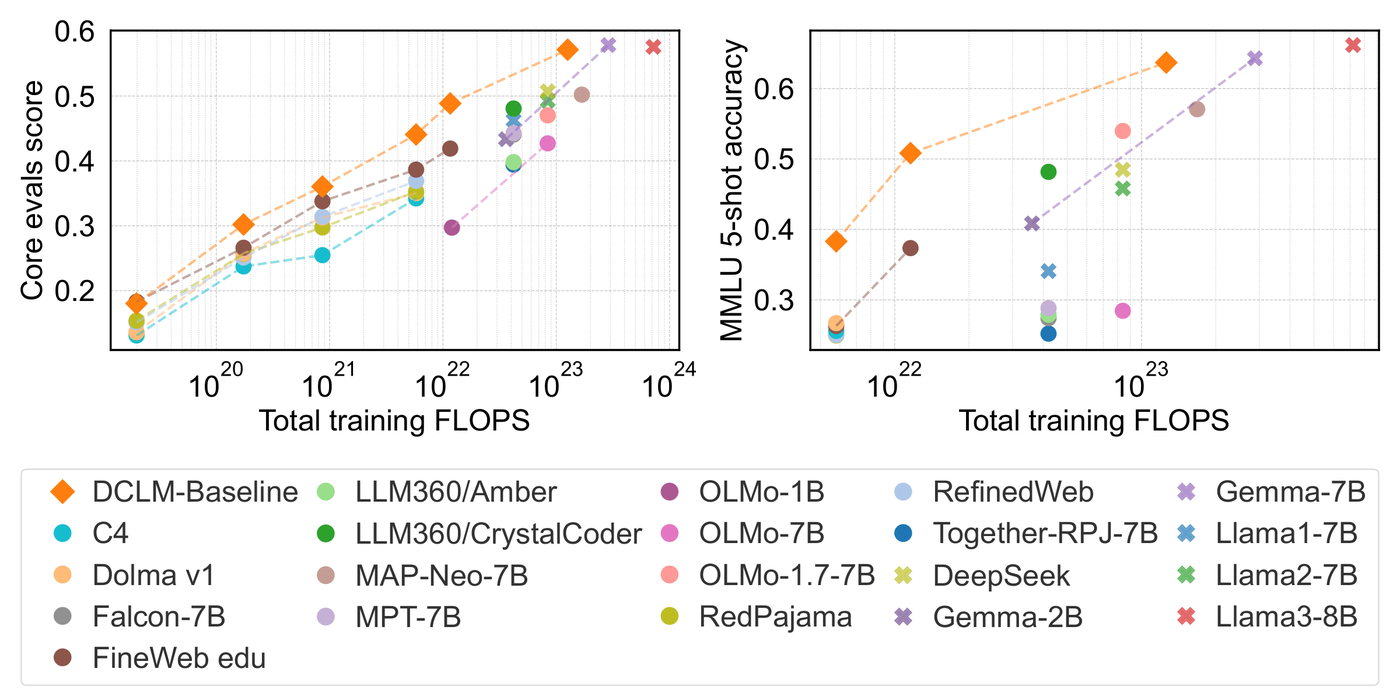
DataComp-LM: In Search of the Next Generation of Training Sets for Language Models
NeurIPS 2024
paper
code
|
|
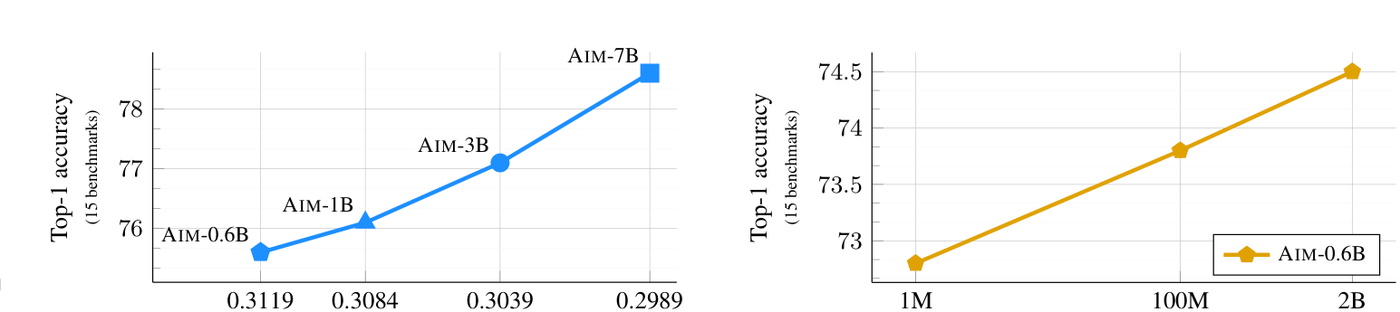
Scalable Pre-training of Large Autoregressive Image Models
ICML 2024
paper
code
|
|
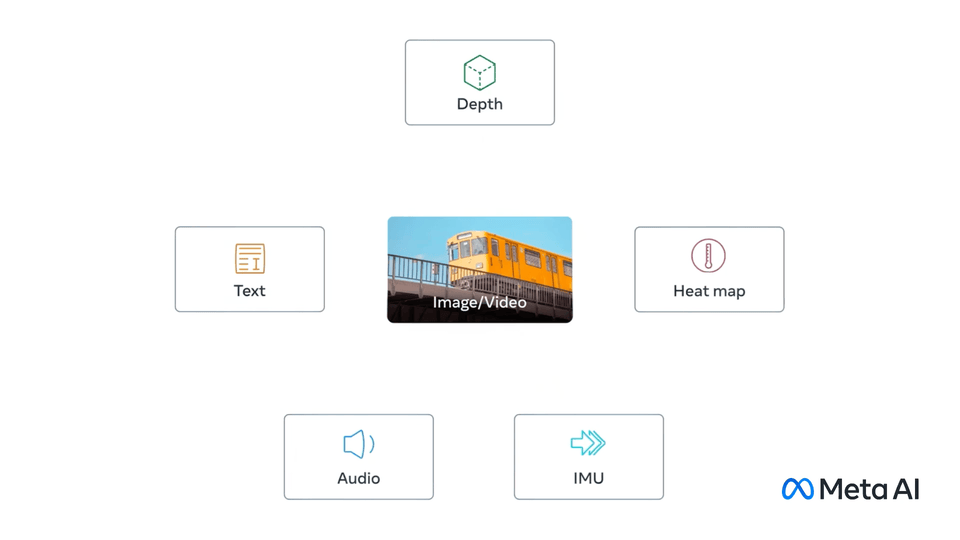
ImageBind: One Embedding Space To Bind Them All
CVPR 2023
Highlight
paper
code
|

|
DINOv2: Learning Robust Visual Features without Supervision
Preprint
paper
code
|

|
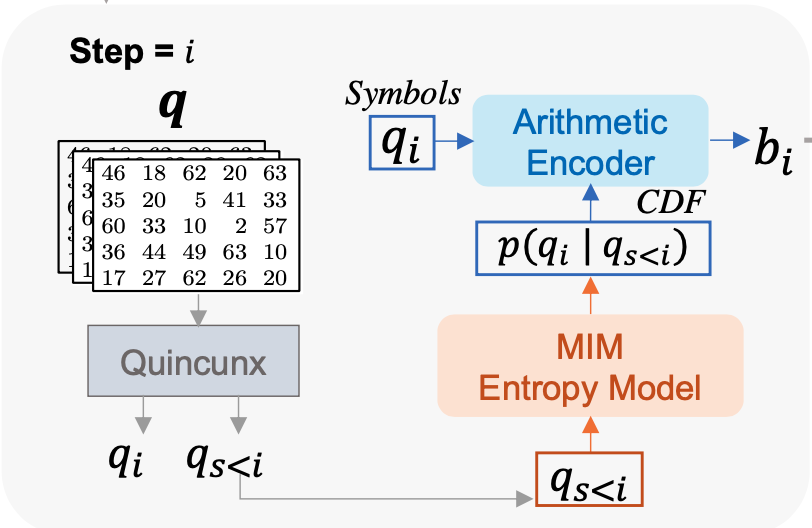
Improving Statistical Fidelity for Neural Image Compression with Implicit Local Likelihood Models
ICML 2023
paper
|
|
Image Compression with Product Quantized Masked Image Modeling
Transactions of Machine Learning Research (TMLR)
paper
|
|
OmniMAE: Single Model Masked Pretraining on Images and Videos
CVPR 2023
paper
code
|
|
Three things everyone should know about Vision Transformers
ECCV 2022
paper
code
|
|
Are Large-scale Datasets Necessary for Self-Supervised Pre-training?
Under Review
paper
|
|
XCiT: Cross-Covariance Image Transformer
NeurIPS 2021
paper
video
code
|
|
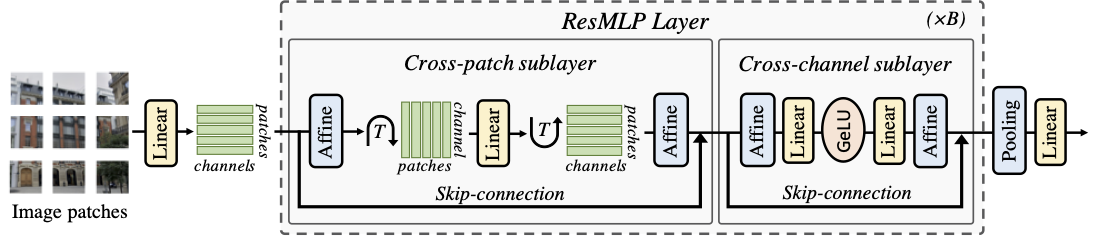
ResMLP: Feedforward networks for image classification with data-efficient training
TPAMI
paper
code
|
|
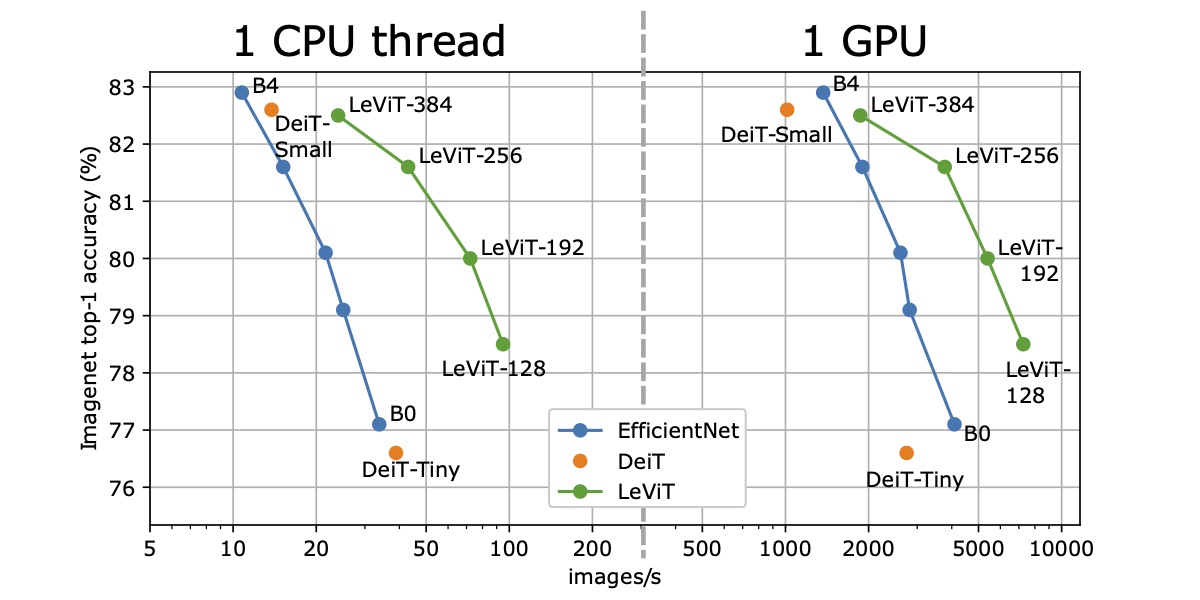
LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference
ICCV 2021
paper
code
|
|
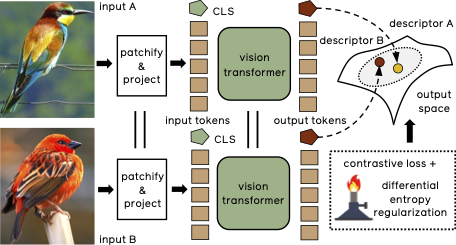
Training Vision Transformers for Image Retrieval
Preprint
paper
|
|
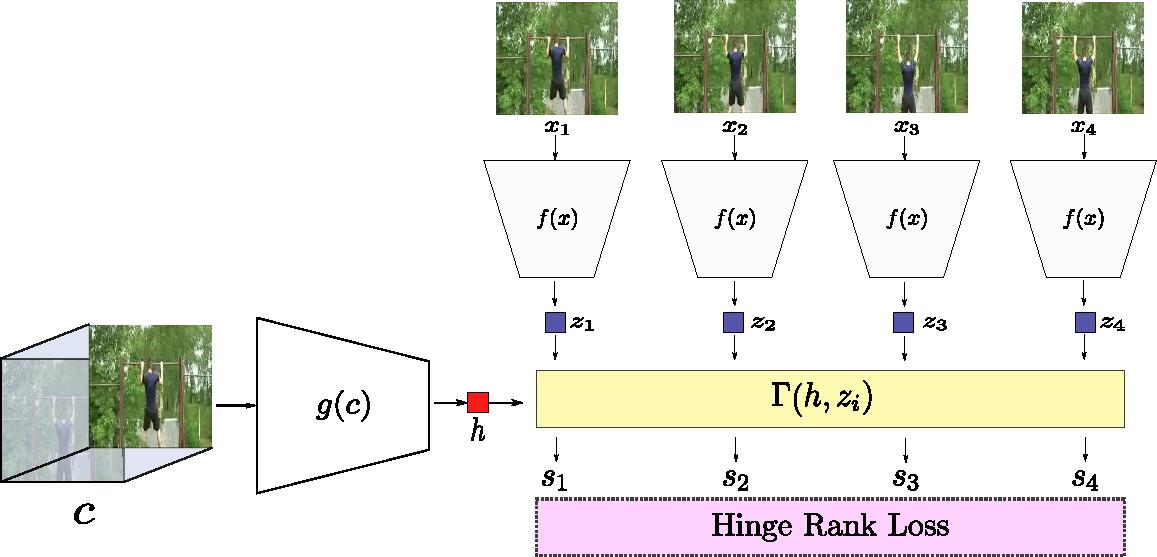
Skip-Clip: Self-Supervised Spatiotemporal Representation Learning by Future Clip Order Ranking
Holistic Video Understanding Workshop ICCV2019 (Best poster Award)
paper
poster
bibtex
|
|
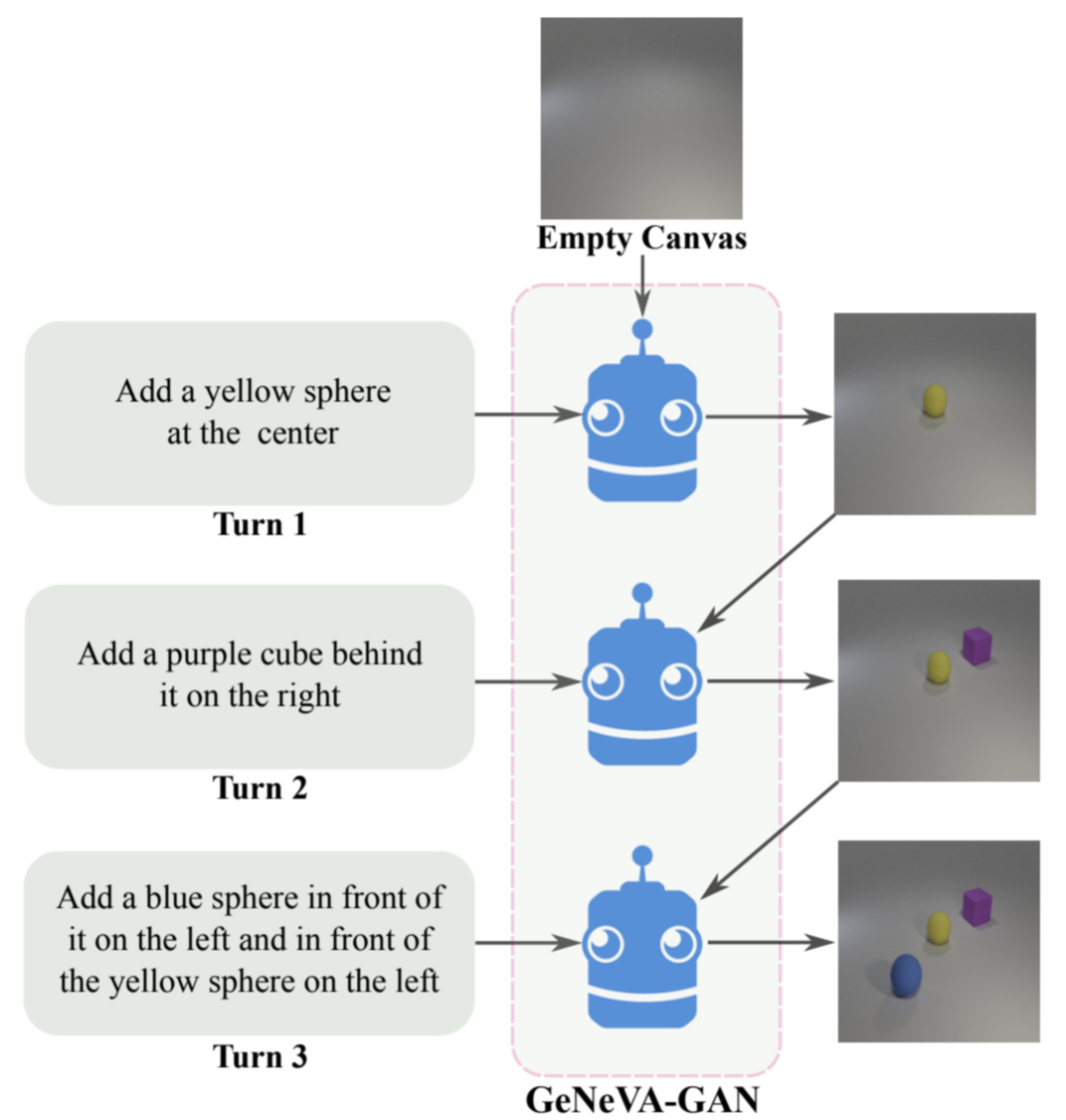
Tell, Draw, and Repeat: Generating and Modifying Images Based on Continual Linguistic Instruction
Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV)
paper
code
poster
blog
bibtex
|
|
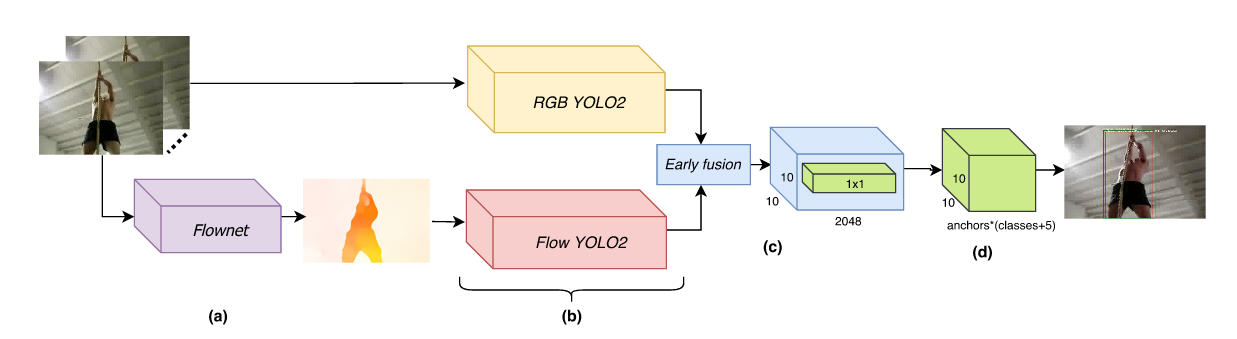
Real-Time End-to-End Action Detection with Two-Stream Networks
15th Conference on Computer and Robot Vision, CRV 2018
Oral
paper
bibtex
|

|
Spatiotemporal Representation Learning For Human Action Recognition And Localization |
Invited Talks
|
Reviewing
|
|
Design and source code from Jon Barron's website |